
|
|
|
|
|
|
|
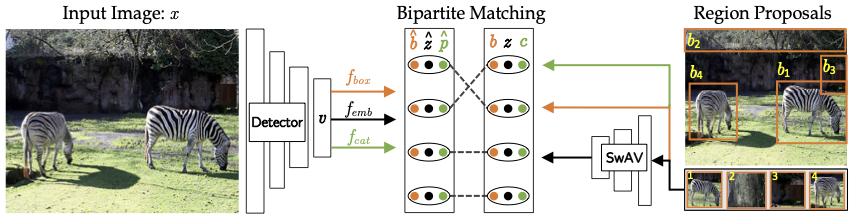
Our approach to the problem is based on the observation that learning good detectors requires learning to detect objects in the pretraining stage. To accomplish this, we present a new framework called ``DEtection with TRansformers based on Region priors'', or DETReg. DETReg can be used to train a detector on unlabeled data by introducing two key pretraining tasks: ``Object Localization Task'' and the ``Object Embedding Task''. The goal of the first is to train the model to localize objects, regardless of their categories. However, learning to localize objects is not enough, and detectors must also classify objects. Towards this end, we introduce the ``Object Embedding Task'', which is geared towards understanding the categories of objects in the image. Inspired by the simplicity of recent transformers for object detection, we choose to base our approach on the Deformable DETR architecture, which simplifies the implementation and is very fast to train.
Qualitative examples of DETReg unsupervised box predictions. This shows the pixel-level gradient norm for the x/y bounding box center and the object embedding. These gradient norms indicate how sensitive the predicted values are to perturbations of the input pixels. For the first three columns, DETReg attends to the object edges for the x/y predictions and z for the predicted object embedding. The final column shows a limitation where the space surrounding the object is used for the embedding.

 |
DETReg: Unsupervised Pretraining with Region Priors for Object Detection Amir Bar, Xin Wang, Vadim Kantorov, Colorado J Reed, Roei Herzig, Gal Chechik, Anna Rohrbach, Trevor Darrell, Amir Globerson Arxiv Hosted on arXiv |
| If you found our work interesting, please also consider looking into some closely related works like RegionSim, UP-DETR, SwAV. |
Acknowledgements |